El estilo puede cambiar entre objetos pero no debe cambiar al objeto.
Cuando hablamos de temas abstractos, cada quien tiene su verdad.
Algo que me llamó mucho la atención fue como estos conceptos: qué es un estilo y un objeto se pueden representa con matemáticas.
Vamos a ello.
Qué red podemos usar para la transferencia de estilos?
Consideremos los siguientes puntos:
1) utilizaremos un modelo para imágenes (VGG19) -> convolucionales
2) y reutilizaremos un modelo que puede distinguir entre una gran cantidad de objetos (ImageNet)→ transfer learning
3) un modelo que pueda combinar dos imágenes, manteniendo el estilo de una imagen y los objetos de la otra imagen.
3.1) Necesitamos verificar que se esté haciendo lo que le pedimos, para ello necesitamos métricas para la transferencia de estilos:
Content loss:
La imagen combinada debe tener el mismo contenido que la imagen base.
Style loss:
La imagen combinada debe tener el mismo estilo que la imagen de estilo.
Total variance loss:
La imagen combinada debe tener una representación suave, que no se vea pixelada.
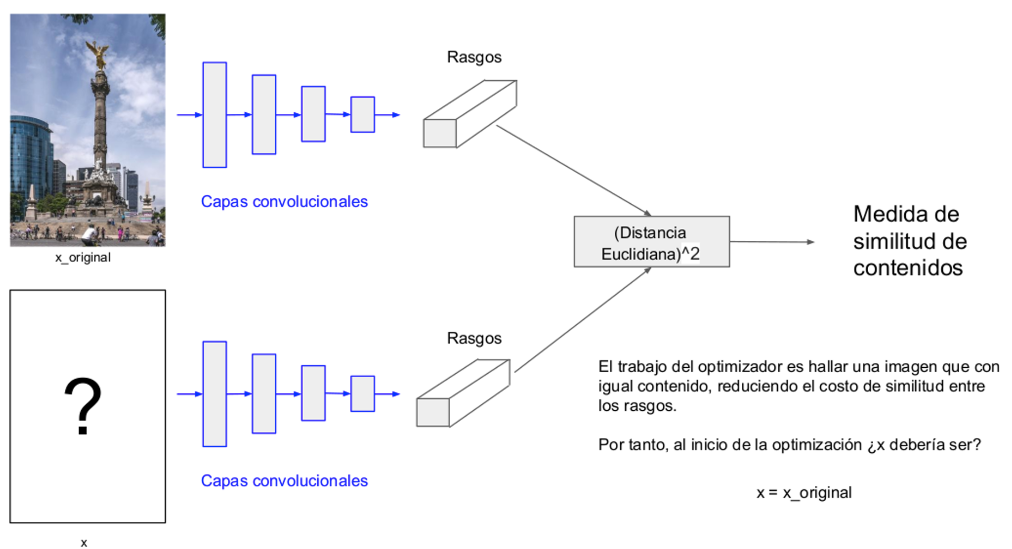
3.1.1) Cómo medir la similitud de contenidos entre dos imágenes?
3.1.2) Cómo medir la similitud de estilos entre dos imágenes?
y volvemos a la pregunta …
El estilo se puede ver, como la similitud de patrones (textura), que hay entre distintas partes de la misma imagen.
No conviene trabajar a nivel de pixeles, sería mejor a nivel de rasgos representativos de los patrones. Porque los pixeles no tienen la información suficiente que define la textura de toda la imagen.
Cómo representamos matemáticamente el estilo de cada autor?
la matriz G, porqué?
Porque esta matriz contiene las correlaciones entre distintos patrones (texturas) existentes en la imagen. Cada neurona es sensible a un patrón de pixeles y cada una genera un mapa de rasgos diferentes.
Con toda esta información ahora ya podemos responder la pregunta: ¿Cómo medir la similitud de estilos entre dos imágenes?
3.1.3) Cómo medir la calidad de la imagen?
Para garantizar, durante la optimización, la imagen no genera cambios abruptos entre pixeles vecinos -> se penaliza la disimilitud entre pixeles en x.
La VGG19 es una arquitectura de red neuronal convolucional (CNN) que pertenece a la familia de modelos VGG (Visual Geometry Group).
El número «19» en VGG19 se refiere al hecho de que la red tiene 19 capas.
Descripción general de las capas que se utilizan en VGG19:
Capas de entrada (Input Layer): Representan la imagen de entrada y tienen la dimensión correspondiente a las imágenes que se están utilizando.
Capas convolucionales (Convolutional Layers): VGG19 utiliza una serie de capas convolucionales para extraer características de las imágenes. Estas capas aplican filtros convolucionales para detectar patrones locales en la imagen.
Capas de activación ReLU (Rectified Linear Unit): Después de cada capa convolucional, se aplica una función de activación ReLU para introducir no linealidades en la red y permitir la modelación de relaciones más complejas en los datos.
Capas de agrupación (Pooling Layers): VGG19 utiliza capas de agrupación máxima (max pooling) para reducir las dimensiones espaciales de las representaciones aprendidas, disminuyendo así la cantidad de parámetros y computaciones en la red.
Capas totalmente conectadas (Fully Connected Layers): Después de las capas convolucionales y de agrupación, VGG19 tiene capas completamente conectadas que actúan como clasificadores finales. Estas capas toman las características aprendidas y las utilizan para clasificar la imagen en categorías específicas.
Capa de salida (Output Layer): La capa de salida es una capa softmax que produce la distribución de probabilidad sobre las clases para la clasificación.
La estructura profunda y uniforme de VGG19 con capas convolucionales repetidas y pequeños filtros convolucionales la hace eficaz en la extracción de características complejas de las imágenes.
Implementación de un modelo transfer learning.
Ya tenemos las funciones de costo operando correctamente, necesitamos optimizarlas ¿Cómo?
Cargar el modelo neuronal pre-entrenado (vgg19) y darle las tres imágenes de entrada (imagen original, imagen con estilo, imagen nueva)
def preprocess_image(image_path):
# Convierte las imagenes en el formato necesario para procesarlas, ademas de convertirlas en tensores
img = keras.preprocessing.image.load_img(
image_path, target_size=(img_nrows, img_ncols)
)
img = keras.preprocessing.image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg19.preprocess_input(img)
return tf.convert_to_tensor(img)
base_image = preprocess_image(base_path)
style_reference_image = preprocess_image(estilo_path)
# la imagen combinada al inicio es la imagen base
combination_image = tf.Variable(preprocess_image(base_path))
Construir la función de costo total (y añadirla al grafo del modelo cargado).
# The gram matrix of an image tensor (feature-wise outer product)
def gram_matrix(x):
x = tf.transpose(x, (2, 0, 1))
features = tf.reshape(x, (tf.shape(x)[0], -1))
gram = tf.matmul(features, tf.transpose(features))
return gram
# The "style loss" is designed to maintain
# the style of the reference image in the generated image.
# It is based on the gram matrices (which capture style) of
# feature maps from the style reference image
# and from the generated image
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = img_nrows * img_ncols
return tf.reduce_sum(tf.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
# An auxiliary loss function
# designed to maintain the "content" of the
# base image in the generated image
def content_loss(base, combination):
return tf.reduce_sum(tf.square(combination - base))
# The 3rd loss function, total variation loss,
# designed to keep the generated image locally coherent
def total_variation_loss(x):
a = tf.square(
x[:, : img_nrows - 1, : img_ncols - 1, :] - x[:, 1:, : img_ncols - 1, :]
)
b = tf.square(
x[:, : img_nrows - 1, : img_ncols - 1, :] - x[:, : img_nrows - 1, 1:, :]
)
return tf.reduce_sum(tf.pow(a + b, 1.25))
def compute_loss(combination_image, base_image, style_reference_image):
input_tensor = tf.concat(
[base_image, style_reference_image, combination_image], axis=0
)
features = feature_extractor(input_tensor)
# Inicializar las perdidas
loss = tf.zeros(shape=())
# Add content loss
layer_features = features[content_layer_name]
base_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss = loss + content_weight * content_loss(
base_image_features, combination_features
)
# Add style loss
for layer_name in style_layer_names:
layer_features = features[layer_name]
style_reference_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_reference_features, combination_features)
loss += (style_weight / len(style_layer_names)) * sl
# Add total variation loss
loss += total_variation_weight * total_variation_loss(combination_image)
return loss
Declarar una función para invertir el pre-procesamiento de la imagen x.
def deprocess_image(x):
# Convirte el tensor resultante en un formato mas como para las imagenes
x = x.reshape((img_nrows, img_ncols, 3))
# Remove zero-center by mean pixel
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
# 'BGR'->'RGB'
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype("uint8")
return x
Optimizar el costo total (mediante el método L-BFGS-B)
@tf.function
def compute_loss_and_grads(combination_image, base_image, style_reference_image):
with tf.GradientTape() as tape:
loss = compute_loss(combination_image, base_image, style_reference_image)
grads = tape.gradient(loss, combination_image)
return loss, grads
optimizer = keras.optimizers.SGD(
keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=100.0, decay_steps=100, decay_rate=0.96
)
)
base_image = preprocess_image(base_path)
style_reference_image = preprocess_image(estilo_path)
# la imagen combinada al inicio es la imagen base
combination_image = tf.Variable(preprocess_image(base_path))
iterations = 4000
for i in range(1, iterations + 1):
loss, grads = compute_loss_and_grads(
combination_image, base_image, style_reference_image
)
optimizer.apply_gradients([(grads, combination_image)])
if i % 100 == 0:
print("Iteration %d: loss=%.2f" % (i, loss))
img = deprocess_image(combination_image.numpy())
fname = result_prefix + "_at_iteration_%d.png" % i
keras.preprocessing.image.save_img(fname, img)
Combinando una foto de la catedral de Cajamarca y la pintura de la noche estrellada de Van Gogh: